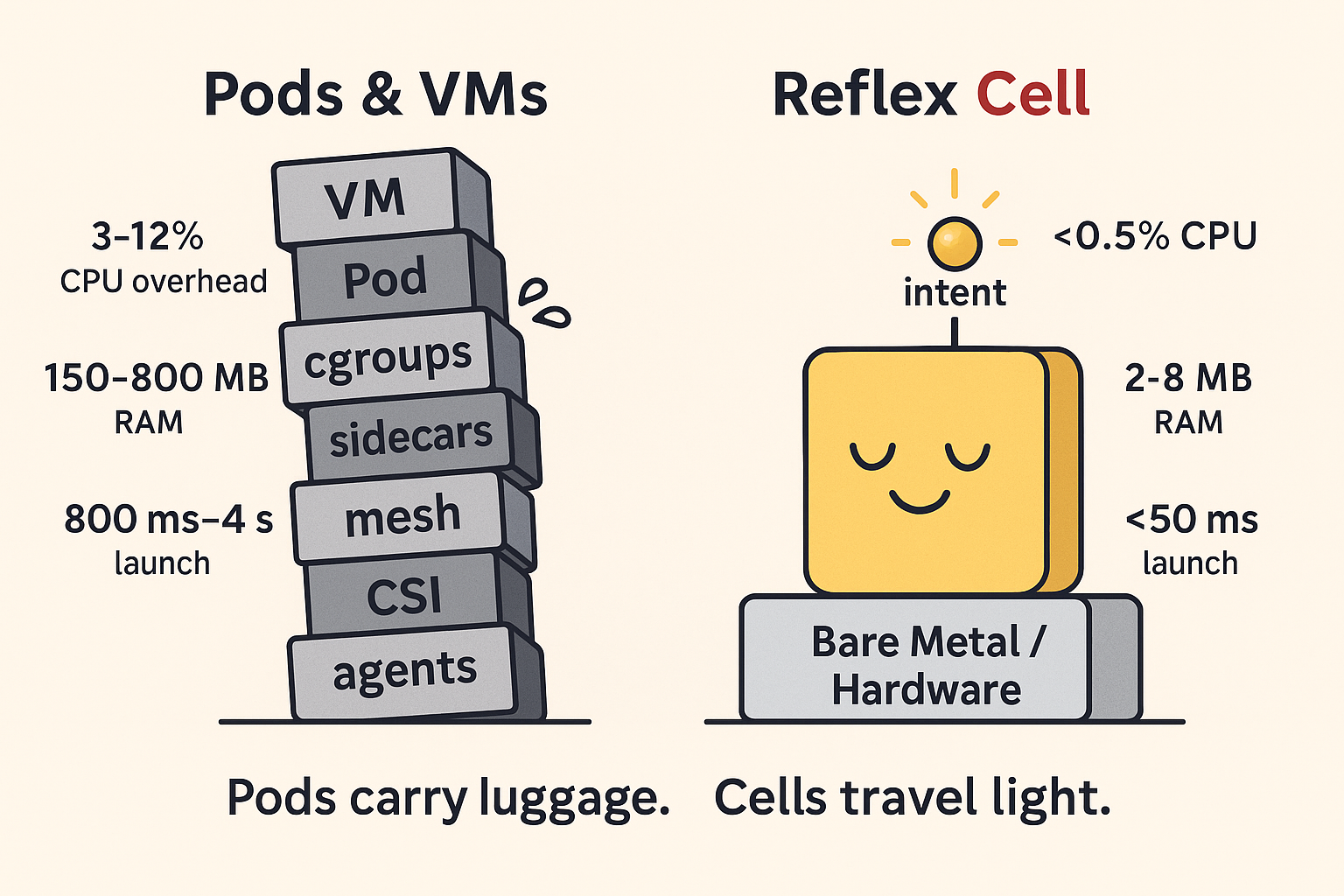
Resource Efficiency — Cell vs Pod/VM
Reflex Cells run closer to the metal with far less orchestration noise.
| Resource Dimension | Traditional (K8s Pod + cgroups + optional VM) | Celluster Reflex Cell (bare-metal, no Pod, no VM) | Net Winner & Real-World Delta |
|---|---|---|---|
| CPU overhead | 3–12% lost to kubelet, containerd, sidecars & cgroup accounting. | < 0.5% (lightweight Reflex arc + minimal runtime). | Celluster → 5–20× less CPU burn for “management.” |
| Memory overhead | 150–800 MB per Pod (runtime, buffers, mesh, agents). | 2–8 MB per Cell (lineage table + intent state). | Celluster → 50–100× less RAM per unit of work. |
| GPU direct path | Device plugins, IOMMU, scheduler hops, and indirection. | Native RDMA/XDP paths; no hypervisor, no KVM in the hot path. | Celluster → 3–8% higher effective TOPS. |
| Storage / IO overhead | OverlayFS, CSI driver chains, and indirection on every call. | Direct NVMe/SSD passthrough bound to intent semantics. | Celluster → 2–4× higher IOPS for hot paths. |
| Network stack | veth + bridge + iptables/eBPF + sometimes sidecar mesh. | intent with mTLS — no mesh sidecar. | Celluster → 400k–1M+ pps/core sustained. |
| Launch latency | 800 ms – 4 s (scheduler → kubelet → containerd → Pod). | Sub-50 ms (intent → Reflex spawn on target node). | Celluster → 20–100× faster cold start paths. |
| Tenant isolation | cgroups + namespaces + optional VM (still shared kernel). | Lineage + semantic identity + Reflex membrane semantics. | Celluster → stronger isolation at lower cost. |
| Utilization in practice | Real clusters: ~35–55% effective GPU/CPU utilization. | Pilots targeting 85–96% sustained under production load. | Celluster → 1.6–2.7× more billable work per rack. |
Numbers based on public cloud reports + Celluster claims. Pods work great, they just carry a lot of luggage. Cells travel light. Choose your journey.
Numbers are directional, based on typical large-cluster behavior and early prototype estimates. Exact gains depend on workload mix, fabrics, and integration depth.
Why People Think “No Pod = Less Safe / Less Efficient”
It’s mostly Kubernetes religion, not physics.
Kubernetes taught the world: “Pods are the atomic unit of isolation and scheduling.” That made sense in the Docker + early cgroup era. But Pods inherit all the historical baggage of that stack.
- Myth: No Pod means no isolation.
Reflex: Intent + lineage + cryptographic identity give stronger, verifiable isolation than namespace tricks and IP-based policies. - Myth: Pods are necessary for efficiency.
Reflex: Pods and VMs add layers of orchestration tax — schedulers, daemons, cgroups, overlay filesystems, sidecars. Cells embed coordination directly into semantics, not control loops. - Myth: GC and eviction need kubelet.
Reflex: Reflex GC reclaims resources in < 1 s based on lineage and intent, instead of waiting on periodic eviction / reconciliation cycles.
The Cell is smaller, faster, safer, and denser than a Pod or VM can ever be when they’re carrying decades of orchestration habits on their back.
Bottom Line
Pods and VMs are wasting your hardware and your security budget.
Once clusters grow and GPUs become the main cost center, the orchestration stack (Pods, VMs, mesh, agents) quietly eats a double-digit percentage of CPU, RAM, IOPS, and engineering time.
Celluster flips that equation:
- More compute per watt — less time feeding schedulers and sidecars.
- Stronger multi-tenancy — semantics and lineage instead of only kernel namespaces.
- Zero orchestration tax as a design goal, not an optimization afterthought.
- Effectively “infinite” density relative to Pods/VMs, bounded by physics not layers.
You don’t buy GPUs to simulate control planes, you buy them to run models. Cells keep the metal honest.